요약
- 멀티 밸류 인덱스에 대해 이해하게 됨.
- 하나의 데이터 레코드에 여러 개의 키 값을 가질 수 있음.
- ex) JSON 포맷의 데이터에 멀티 밸류 인덱스를 지원함.
- 클러스터링 인덱스에 대해 이해하게 됨.
- 클러스터링 인덱스는 테이블의 프라이머리 키에대해서만 적용됨
- 프라이머리 키 값에 의해 레코드 저장위치가 결정됨.
- 프라이머리 키가 없다면 InnoDB 스토리지 엔진이 내부적으로 대체할 칼럼에 대한 일련번호를 부여함
- 대신, 사용자가 이 값을 알 방법이 없어서 크게 의미가 없음.
- 세컨더리 인덱스에 대해 이해하게 됨.
- 세컨더리 인덱스는 레코드의 주소를 가지고 있음.
- InnoDB 스토리지 엔진에서 세컨더리 인덱스가 레코드의 주소를 알고 있다면 클러스터링 키 값이 변경되면 주소 값 자체를 계속 변경해야함. → 오버헤드 발생
- 따라서 세컨더리 인덱스는 프라이머리 키 값을 바라보도록 해서 오버헤드를 줄인다.
- 세컨더리 인덱스는 레코드의 주소를 가지고 있음.
- 클러스터링 인덱스의 장단점을 이해하게 됨.
- 장점 : 프라이머리 키에 대한 검색 성능이 매우 빠름
- 장점 : 세컨더리 인덱스를 이용한 커버링 인덱스를 이용할 수 있음.
- 단점 : 쓰기 작업이 느림
- 클러스터링 테이블 사용시 주의사항을 알게됨.
- 클러스터링 인덱스 키 크기를 잘 고려해야 함.
- AUTO-INCREMENT 보다는 업무적인 키값을 사용하자.
- 프라이머리 키 값을 반드시 명시하자.
- AUTO-INCREMENT 인조 식별자를 사용하자.
메모
멀티 밸류 인덱스
- 전문 검색 인덱스를 제외한 인덱스는 레코드 1건이 1개의 인덱스 키 값을 가짐.
- 즉, 인덱스와 데이터 레코드는 1:1 관계를 가짐.
- 멀티 밸류(Multi-Value) 인덱스는 하나의 데이터 레코드가 여러 개의 키값을 가질 수 있는 형태의 인덱스임.
- 일반 DBMS 기준으로 생각하면 이러한 인덱스는 정규화에 위배되는 형태임.
- 하만, 최근 RDBMS 에서 JSON 데이터 타입을 지원하기 시작하며, JSON 배열 타입의 필드에 저장된 원소들에 대한 인덱스 요건이 발생함.
- JSON 포맷으로 데이터를 저장하는 MongoDB는 처음부터 이런 형태의 인덱스를 지원함.
- MySQL 서버는 멀티 밸류 인덱스에 대한 지원 없이 JSON 타입 칼럼만 지원했음.
- 배열 형태에 대한 인덱스 생성이 되지 않아서 MongoDB의 기능과 많이 비교되곤 함.
- 8.0 버전부터 MySQL 서버의 JSON 관리 기능이, MongoDB에 비해 부족함이 없는 상태가 됨.
- MySQL 서버는 멀티 밸류 인덱스에 대한 지원 없이 JSON 타입 칼럼만 지원했음.
mysql> CREATE TABLE user (
user_id BIGINT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(10),
last_name VARCHAR(10),
credit_info JSON,
INDEX mx_creditscores ( (CAST(credit_info->'$.credit_scores' AS UNSIGNED ARRAY)) )
mysql> INSERT INTO user VALUES (1, 'Matt', 'Lee', '{"credit_scores":[360, 353, 351]}');- 멀티 밸류 인덱스는 반드시 다음 함수들을 이용해서 검색해야, 옵티마이저가 인덱스를 활용한 실행 계획을 수립한다.
- MEMBER OF()
- JSON_CONTAINS()
- JSON_OVERLAPS()
mysql> SELECT * FROM user WHERE 360 MEMBER OF(credit_info->'$.credit_scores');
+---------+------------+-----------+------------------------------------+
| user_id | first_name | last_name | credit_info |
+---------+------------+-----------+------------------------------------+
| 1 | Matt | lee | {"credit_scores": [360, 353, 351]} |
+---------+------------+-----------+------------------------------------+
mysql> EXPLAIN SELECT * FROM user WHERE 360 MEMBER OF(credit_info->'$.credit_scores');
+----+-------------+-------+------+----------------+---------+-------+-------------+
| id | select_type | table | type | key | key_len | ref | Extra |
+----+-------------+-------+-----------------------------------------+-------------+
| 1 | SIMPLE | user | ref | mx_creditscore | 9 | const | Using where |
+----+-------------+-------+------+----------------+---------+-------+-------------+- 위 예제에서, MEMBER OF() 연산자를 사용함.
- 멀티 밸류 인덱스를 활용한 실행 계획이 만들어짐.
클러스터링 인덱스
- 클러스터링이란, 여러 개를 하나로 묶는다는 의미
- MySQL 서버에서 클러스터링은 테이블의 레코드를 비슷한 것(프라이머리 키 기준으로)들 끼리 묶어서 저장하는 형태로 구현됨.
- 주로, 동시에 조회하는 경우가 많다는 점에서 착안한 것임.
- MySQL에서 클러스터링 인덱스는 InnoDB 스토리지 엔진에서만 지원함.
- 나머지 스토리지 엔진에서는 지원되지 않음.
- 클러스터링 인덱스는 테이블의 프라이머리 키에 대해서만 적용되는 내용임.
- 즉, 프라이머리 키 값이 비슷한 레코드 끼리 묶어 저장하는 것을 클러스터링 인덱스라 함.
- 중요한것은, 프라이머리 키 값에 의해 레코드 저장위치가 결정됨
- 프라이머리 키 값이 변경되면, 그 레코드의 물리적인 저장 위치가 바뀌어야 함.
- 프라이머리 키 값으로 클러스터링된 테이블은 프라이머리 키 값 자체에 대한 의존도가 상당히 큼.
- 신중히 프라이머리 키를 결정해야 함.
MySQL 서버에서 인덱스(index)와 키(key)는 동의어로 사용됨. 그래서 클러스터링 인덱스는 클러스터링 키라고도 함.
- 클러스터링 인덱스는 사실 인덱스 알고리즘이라기보다, 테이블 레코드의 저장 방식이라 볼 수 있음.
- 그래서 “클러스터링 인덱스”와 “클러스터링 테이블”은 동의어로 사용되기도 함.
- 일반적으로 InnoDB와 같이 항상 클러스터링 인덱스로 저장되는 테이블은 프라이머리 키 기반의 검색이 매우 빠름.
- 대신, 레코드의 저장이나 프라이머리 키의 변경이 상대적으로 느림.
일반적으로 B-Tree 인덱스도 인덱스 키 값으로 이미 정렬되어 저장됨. 이 또한, 어떻게 보면 인덱스의 키 값으로 클러스터링 된 것으로 생각할 수 있음.
하지만, 이렇게 일반적인 B-Tree 인덱스를 클러스터링 인덱스라고 부르지 않음. 테이블의 레코드가 프라이머리 키 값으로 정렬되어 저장된 경우만 “클러스터링 인덱스” 라고 함.

- 위 그림은 클러스터링 테이블의 구조를 그림으로 표현한 것이다.
- 클러스터링 테이블 구조 자체는 B-Tree와 비슷함.
- 하지만 세컨더리 인덱스를 위한 B-Tree의 리프 노드와 달리, 위 그림은 클러스터링 인덱스의 리프 노드에, 레코드의 모든 칼럼이 같이 저장되어 있다.
- 즉, 클러스터링 테이블은 그 자체가 하나의 거대한 인덱스 구조로 관리되고 있는 것임.
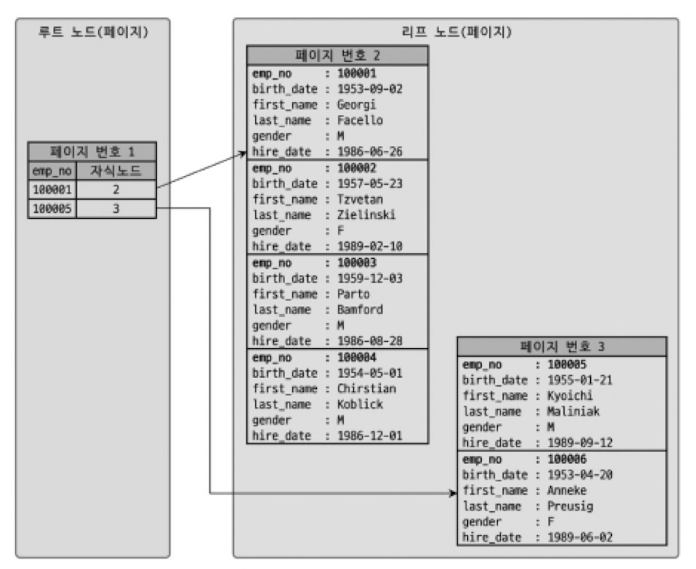
- 위 그림은 아래 UPDATE 쿼리가 실행된 상황이다.
mysql> UPDATE tb_test SET emp_no=10002 WHERE emp_no=100007;- emp_no 가 100007이 원래 페이지 3에 있었는데, 100002로 바뀌면서, 페이지 2로 옮겨진 모습임.
- 실제로 프라이머리 키 값이 변경되는 경우는 거의 없음.
MyISAM 테이블이나 기타 InnoDB를 제외한 테이블의 데이터 레코드는 프라이머리 키나 인덱스 키 값이 변경되어도 실제 데이터 레코드 위치는 변경되지 않음.
데이터 레코드가 INSERT 될 때, 데이터 파일의 끝 또는 임의의 빈공간에 저장됨. → 한번 결정된 위치는 절대 바뀌지 않고, MySQL 내부적으로 레코드를 식별하는 아이디로 인식됨.
이 레코드가 저장된 주소를 로우 아이디(ROW-ID) 라고표현함. 일부 DBMS 에서는 이 값으로 사용자가 직접 조회하거나 쿼리 조건으로 사용할 수 있음. 하지만 MySQL 에서는 사용자에게 노출되지 않음.
- 프라이머리 키가 없는 경우, InnoDB 스토리지 엔진이 다음 우선순위대로 프라이머리 키를 대체할 칼럼을 선택함.
- 프라이머리 키가 있으면, 기본적으로 프라이머리 키를 클러스터링 키로 선택한다.
- NOT NULL 옵션의 유니크 인덱스(UNIQUE INDEX) 중, 첫 번째 인덱스를 클러스터링 키로 선택한다.
- 자동으로 유니크한 값을 가지도록 증가되는 칼럼을 내부적으로 추가한 후, 클러스터링 키로 선택한다.
- InnoDB 스토리지 엔진이 적절한 클러스터링 키 후보를 찾지 못하면, 내부적으로 레코드의 일련번호 칼럼을 생성한다.
- 이렇게 자동 추가된 프라이머리 키(일련번호 카럼)는 사용자에게 노출되지 않음.
- 또, 쿼리 문장에 명시적으로 사용할 수 없음.
- 즉, 프라이머리 키나 유니크 인덱스가 전혀 없는 InnoDB 테이블에서는 아무 의미 없는 숫자로 클러스터링 되는 것임. → 우리에게 어떤 혜택도 주지 않음.
- InnoDB 테이블에서 클러스터링 인덱스는 테이블당 단 하나만 가질 수 있는 엄청난 혜택이므로 가능한 프라이머리 키를 명시적으로 생성하자.
세컨더리 인덱스에 미치는 영향
- 프라이머리 키가 데이터 레코드에 저장에 미치는 영향을 살펴봄.
- 프라이머리 키가 세컨더리 인덱스(Secondary index)에 어떤 영향을 미치는지 살펴보자.
- 프라이머리 키나 세컨더리 인덱스의 각 키는 내부적인 레코드 아이디이자 주소(ROWID)를 이용하여 실제 데이터 레코드를 찾아옴.
- 그래서 MyISAM 테이블이나 MEMORY 테이블에서는 프라이머리 키와 세컨더리 인덱스는 구조적으로 아무런 차이가 없음.
- 만약, InnoDB 테이블에서 세컨더리 인덱스가 실제 레코드가 저장된 주소를 가지고 있다면 어떻게 될까?
- 클러스터링 키 값이 변경될 때마다 데이터 레코드의 주소가 변경되고, 그때마다 해당 테이블의 모든 인덱스에 저장된 주솟값을 변경해야 할 것임.
- 이런 오버헤드를 제거하기 위해 InnoDB 테이블(클러스터링 테이블)의 모든 세컨더리 인덱스는 해당 레코드가 저장된 주소가 아니라 프라이머리 키 값을 저장하도록 구현되어 있음.
- p274에 MyISAM과 InnoDB 에 대한 인덱스 조회 처리 방식이 잘 설명되어 있음.
클러스터링 인덱스의 장점과 단점
- 장점
- 프라이머리 키(클러스터링 키)로 검색할 때, 처리 성능이 매우 빠름. (특히, 프라이머리 키를 범위 검색하는 경우 매우 빠름)
- 테이블의 모든 세컨더리 인덱스가 프라이머리 키를 가지고 있기에 인덱스만으로 처리되는 경우가 많음. (이를
커버링 인덱스라고 함.)
- 단점
- 테이블의 모든 세컨더리 인덱스가 클러스터링 키를 갖기 때문에 클러스터링 키 값의 크기가 클 경우, 전체적으로 인덱스의 크기가 커짐.
- 세컨더리 인덱스를 통해 검색할 때, 프라이머리 키로 다시 한번 검색해야 하므로 처리 성능이 느림.
- INSERT 할 때, 프라이머리 키에 의해 레코드의 저장 위치가 결정되므로 처리 성능이 느림
- 프라이머리 키를 변경할 때 레코드를 DELETE 하고 INSERT 하는 작업이 필요하기에 처리 성능이 느림.
클러스터링 테이블 사용 시 주의사항
- MyISAM 과 같이 클러스터링되지 않은 테이블에 비해 InnoDB 테이블(클러스터링 테이블)에서는 조금 더 주의해야할 사항이 있음.
클러스터링 인덱스 키의 크기
- 클러스터링 테이블의 경우, 모든 세컨더리 인덱스가 프라이머리 키(클러스터링 키) 값을 포함함.
- 따라서 프라이머리 키 크기가 커지면 세컨더리 인덱스도 자동으로 크기가 커짐.
- 일반적으로 테이블에 세컨더리 인덱스가 4~5개 정도 생성되는걸 고려하면 세컨더리 인덱스 크기는 급격히 증가할 수 있음.
| 프라이머리 키 크기 | 레코드당 증가하는 인덱스 크기 | 100만 건 레코드 저장 시 증가하는 인덱스 크기 |
|---|---|---|
| 10바이트 | 10바이트 * 5 = 50바이트 | 50바이트 * 1,000,000 = 47MB |
| 50바이트 | 50바이트 * 5 = 250바이트 | 250바이트 * 1,000,000 = 238MB |
- 위 표는 5개의 세컨더리 인덱스를 가지는 테이블의 프라이머리 키가 10바이트인 경우와 50바이트인 경우임.
- 레코드 건수가 100만 건만되도 인덱스 크키가 190MB(238 - 47) 나 증가함.
- 즉, 인덱스가 커질수록 같은 성능을 내기 위해 그만큼의 메모리가 필요해지므로, InnoDB 테이블의 프라이머리 키는 신중하게 선택해야 함.
프라이머리 키는 AUTO-INCREMENT보다는 업무적인 칼럼으로 생성(가능한 경우)
- InnoDB 프라이머리 키는 클러스터링 키로 사용됨.
- 이 값에 의해 레코드 위치가 결정됨.
- 즉, 프라이머리 키로 검색하는 경우(특히 범위로 많은 레코드를 검색하는 경우) 클러스터링 되지 않은 테이블에 비해 매우 빠르게 처리될 수 있음.
- 프라이머리 키는 그 의미만큼이나 중요한 역할을 하기 때문에 대부분 검색에서 상당히 빈번하게 사용되는 것이 일반적임.
- 설령 그 칼럼의 크기가 크더라도 업무적으로 해당 레코드를 대표할 수 있다면, 그 칼럼을 프라이머리 키로 설정하는 것이 좋음.
프라이머리 키는 반드시 명시할 것
- 프라이머리 키는 가능하면 AUTO_INCREMENT 칼럼을 이용해서라도 프라이머리 키는 생성하는 것을 권장함.
- InnoDB 테이블에서 프라이머리 키를 정의하지 않으면 InnoDB 스토리지 엔진이 내부적으로 일련번호 칼럼을 추가한다.
- 이렇게 자동으로 추가된 칼럼은 사용자에게 보이지 않으므로 사용자가 전혀 접근할 수 없음.
- ROW기반 복제나 InnoDB Cluster 에서는 모든 테이블이 프라이머리 키를 가져야만 정상 복제 성능을 보장하므로, 프라이머리 키는 꼭 생성하자.
AUTO-INCREMENT 칼럼을 인조 식별자로 사용할 경우
- 여러 개 칼럼이 복합으로 프라이머리 키가 만들어지는 경우, 프라이머리 키 크기가 길어질 때가 가끔 있음.
- 프라이머리 키 크기가 길어도 세컨더리 인덱스가 필요하지 않다면 그대로 프라이머리 키를 사용하는 것이 좋음.
- 세컨더리 인덱스도 필요하고 프라이머리 키의 크기도 길다면, AUTO_INCREMENT 칼럼을 추가하고, 이를 프라이머리 키로 설정하면 됨.
- 이렇게 프라이머리 키를 대체하기 위해 인위적으로 추가된 프라이머리 키를 인조 식별자(Surrogate key) 라고 함.
- 그리고 로그 테이블과 같이 조회보다는 INSERT 위주의 테이블들은 AUTO_INCREMENT를 이용한 인조 식별자를 프라이머리 키로 설정한느 것이 성능 향상에 도움이 됨.
- 세컨더리 인덱스도 필요하고 프라이머리 키의 크기도 길다면, AUTO_INCREMENT 칼럼을 추가하고, 이를 프라이머리 키로 설정하면 됨.
'Book > Real Mysql 8.0' 카테고리의 다른 글
| 책너두 (Real MySQL 8.0 1권) 27일차 (~295p) (0) | 2023.02.04 |
|---|---|
| 책너두 (Real MySQL 8.0 1권) 26일차 (~284p) (0) | 2023.02.02 |
| 책너두 (Real MySQL 8.0 1권) 24일차 (~267p) (0) | 2023.01.31 |
| 책너두 (Real MySQL 8.0 1권) 23일차 (~257p) (1) | 2023.01.28 |
| 책너두 (Real MySQL 8.0 1권) 22일차 (~246p) (0) | 2023.01.28 |