책너두 (Real MySQL 8.0 1권) 21일차 (~239p)
- Book/Real Mysql 8.0
- 2023. 1. 27.
요약
- 인덱스를 통해 테이블의 레코드를 읽는 건수에 따른 비용의 차이를 알게됨.
- B-Tree 인덱스를 통한 데이터 읽기 방식으로 세가지 방법에 대한 내용을 이해하게 됨.
- 인덱스 레인지 스캔
- 인덱스 풀 스캔
- 루스 인덱스 스캔
- 인덱스 스킵 스캔을 통해 복합 인덱스에 대한 처리 방식을 이해하게 됨.
메모
읽어야 하는 레코드의 건수
- 인덱스를 통해 테이블의 레코드를 읽는 것은, 인덱스를 거치지 않고 바로 테이블의 레코드를 읽는 것보다 높은 비용이 드는 작업임.
- 인덱스를 이용한 읽기의 손익 분기점이 얼마인지 판단이 필요함.
- 일반적인 DBMS 의 옵티마이저에서는 테이블에서 직접 레코드를 1건 읽는 것보다 인덱스를 통해 레코드 1건을 읽는 것이 4~5배 정도 비용이 더 많이 드는 작업인 것으로 예측함. → RDBMS 서버 종류 별로 차이가 있음. MySQL 서버에서는 코스트 모델 설정에 따라 변경될 수도 있음. (10.1.3절에서 설명 예정)
- 즉, 인덱스를 통해 읽어야할 레코드의 건수(= 옵티마이저가 판단한 예상 건수)가 전체 테이블 레코드의 20~25%를 넘어서면 인덱스를 이용하지 않고 테이블을 모두 직접 읽어서 필요한 레코드만 가려내는 (필터링) 방식으로 처리하는것이 효율적임.
- 전체 100만 건의 레코드 가운데 50만 건을 읽어야 하는 작업이 있다고 가정하자.
- 이 작업은 인덱스의 손익 분기점인 20~25%보다 훨씬 크기 때문에 MySQL 옵티마이저는 인덱스를 이용하지 않고 직접 테이블을 처음부터 끝까지 읽어서 처리할 것임.
- 강제로 인덱스를 사용하도록 힌트를 추가해도 성능상 얻을 수 있는 이점이 없음.
- 이러한 작업은 MySQL의 옵티마이저가 기본적으로 힌트를 무시하고 테이블을 직접 읽는 방식으로 처리함.
- 일반적인 DBMS 의 옵티마이저에서는 테이블에서 직접 레코드를 1건 읽는 것보다 인덱스를 통해 레코드 1건을 읽는 것이 4~5배 정도 비용이 더 많이 드는 작업인 것으로 예측함. → RDBMS 서버 종류 별로 차이가 있음. MySQL 서버에서는 코스트 모델 설정에 따라 변경될 수도 있음. (10.1.3절에서 설명 예정)
B-Tree 인덱스를 통한 데이터 읽기
- 경우에 따라 인덱스를 사용하도록 유도할지, 사용 못하게 할지 판단하려면 MySQL (더 정확히는 각 스토리지 엔진)이 어떻게 인덱스를 이용해서 실제 레코드를 읽어 내는지 알아야 함.
- MySQL 이 인덱스를 이용하는 대표적인 방법 세 가지가 있음.
인덱스 레인지 스캔
- 인덱스 레인지 스캔은 인덱스의 접근 방법 가운데 가장 대표적인 접근 방식임.
- 뒤에 설명할 나머지 두 가지 접근 방식보다 빠른 방법임.
- 인덱스를 통한 레코드를 한 건만 읽는 경우와 한 건 이상을 읽는 경우는 각각 다른 이름으로 구분함.
- 이번에 설명하는 것은 모두 묶어서 “인덱스 레인지 스캔” 이라고 표현한다.
- 상세 내용은 10장 ‘실행 계획’에서 언급할 예정.
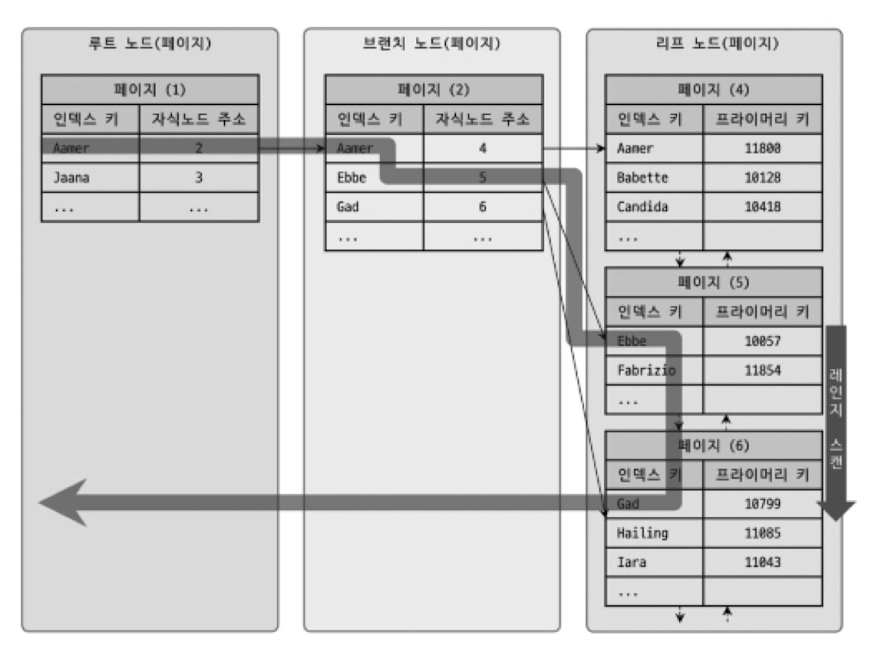
- 위 그림은
SELECT * FROM employees WHERE first_name BETWEEN 'Ebbe' AND 'Gad';쿼리에 대해 인덱스를 이용한 레인지 스캔을 표현한 것임. - 인덱스 레인지 스캔은 검색해야 할 인덱스의 범위가 결정됐을 떄 사용하는 방식임.
- 검색하려는 값의 수나 검색 결과 레코드 건수와 관계 없이 레인지 스캔이라고 표현함.
- 위 그림에서 알수 있듯, 루트노드 → 브랜치 노드 → 리프 노드를 거쳐야만 비로소 필요한 레코드의 시작 지점을 찾을 수 있다.
- 시작해야 할 위치를 찾으면 그때부터는 리프 노드의 레코드만 순서대로 읽으면 됨.
- 이처럼 순서대로 읽는 것을
스캔이라고 표현함. - 만약 스캔하다가 리프 노드의 끝까지 읽으면 리프 노드 간의 링크를 이용해 다음 리프 노드를 찾아서 다시 스캔함.
- 최종적으로 스캔을 멈춰야 할 위치에 다다르면 지금까지 읽은 레코드를 사용자에게 반환하고 쿼리를 끝냄.
- 이처럼 순서대로 읽는 것을
- 시작해야 할 위치를 찾으면 그때부터는 리프 노드의 레코드만 순서대로 읽으면 됨.
- 위 그림은 실제 인덱스만을 읽는 경우임.
- 하지만 B-Tree 인덱스의 리프 노드를 스캔하면서 실제 데이터 파일의 레코드를 읽어 와야 하는 경우도 많음.

- 위 그림은 인덱스 레인지 스캔을 하며 데이터 레코드를 읽는 그림임.
- B-Tree 인덱스에서 루트 → 브랜치 노드를 이용해 스캔 시작 위치를 검색하고, 그 지점부터 필요한 방향 (오름차순 or 내림차순)으로 인덱스를 읽어 나가는 과정을 보여줌.
- 중요한건, 어떤 방식으로 스캔하든 관계없이, 해당 인덱스를 구성하는 칼럼의 정순 또는 역순으로 정렬된 상태로 레코드를 가져온다는 것임.
- 이는 별도의 정렬 과정이 수반된 것이 아님.
- 인덱스 자체의 정렬 특성 때문에 자동으로 되는 것임.
- 중요한건, 어떤 방식으로 스캔하든 관계없이, 해당 인덱스를 구성하는 칼럼의 정순 또는 역순으로 정렬된 상태로 레코드를 가져온다는 것임.
- 위 그림에서 또 하나 중요한 것은, 인덱스의 리프 노드에서 검색 조건에 일치하는 건들은 데이터 파일에서 레코드를 읽어오는 과정이 필요함.
- 이때, 리프 노드에 저장된 레코드 주소로 데이터 파일의 레코드를 읽어옴.
- 레코드 한 건 한 건 단위로 랜덤 I/O가 한 번씩 일어남.
- 그림처럼 3건의 레코드가 검색 조건에 일치했다고 가정하자.
- 데이터 레코드를 읽기 위해 랜덤 I/O가 최대 3번 필요함.
- 그래서 인덱스를 통해 데이터 레코드를 읽는 작업은 비용이 많이 드는 작업으로 분류됨.
- 이때, 리프 노드에 저장된 레코드 주소로 데이터 파일의 레코드를 읽어옴.
- 정리해서, 인덱스 레인지 스캔은 다음과 같이 크게 3단계를 거침.
- 인덱스에서 조건을 만족하는 값이 저장된 위치를 찾는다. → 인덱스 탐색(Index seek) 라고 함.
- 1번에서 탐색된 위치부터 필요한 만큼 인덱스를 차례대로 쭉 읽는다. → 인덱스 스캔(Index scan) 이라고 함. (1,2를 합쳐 인덱스 스캔으로 통칭하기도 함.)
- 2번에서 읽어 들인 인덱스 키와 레코드 주소를 이용해 레코드가 저장된 페이지를 가져오고, 최종 레코드를 읽어옴.
- 작성한 쿼리가 필요로 하는 데이터에 따라 위 3번 과정은 필요하지 않을 수 있음.
- 이를
커버링 인덱스라고함. - 커버링 인덱스로 처리되는 쿼리는 디스크의 레코드를 읽지 않아도 되므로 랜덤 읽기가 상당히 줄어들고 성능도 그만큼 빨라짐.
- 이를
- MySQL 서버에서는 1번과 2번 단계 작업이 얼마나 수행됐는지 확인할 수 있게 상태 값을 제공함.
- Handler_read_key : 1번 단계가 실행된 횟수
- Handler_read_next : 2번 단계가 실행된 횟수 (인덱스 정순으로 읽은 레코드 건수)
- Handler_read_prev : 2번 단계가 실행된 횟수 (인덱스 역순으로 읽은 레코드 건수)
- Handler_read_first : 인덱스의 첫 번째 레코드를 읽은 횟수
- Handler_read_last : 인덱스의 마지막 레코드를 읽은 횟수
- first, last 변수는 MIN(), MAX() 와 같이 제일 크거나 작은 값만 읽는 경우, 증가하는 상태 값임.
- 이 변수들은 실제 인덱스만 읽었는지, 인덱스를 통해 테이블의 레코드를 읽었는지는 구분하지 않음.
인덱스 풀 스캔
- 인덱스 레인지 스캔과 마찬가지로 인덱스를 사용함.
- 하지만 인덱스 레인지 스캔과 달리 인덱스의 처음부터 끝까지 모두 읽는 방식이다.
- 대표적으로 쿼리의 조건절에 사용된 칼럼이 인덱스의 첫 번째 칼럼이 아닌 경우 인덱스 풀 스캔 방식이 사용됨.
- ex) 인덱스가 (A, B, C) 칼럼 순으로 만들어 져있는데, 쿼리의 조건절에서 B, 혹은 C 칼럼으로 검색하는 경우임.
- 일반적으로 인덱스의 크기는 테이블 크기보다 작다.
- 직접 테이블을 처음부터 끝까지 읽는 것보다는 인덱스만 읽는 것이 효율적임.
- 쿼리가 인덱스에 명시된 칼럼만으로 조건을 처리할 수 있는 경우, 이 방식을 사용함.
- 인덱스뿐만 아니라 데이터 레코드까지 모두 읽어야 한다면, 이 방식으로 처리되지 않음.
- 직접 테이블을 처음부터 끝까지 읽는 것보다는 인덱스만 읽는 것이 효율적임.
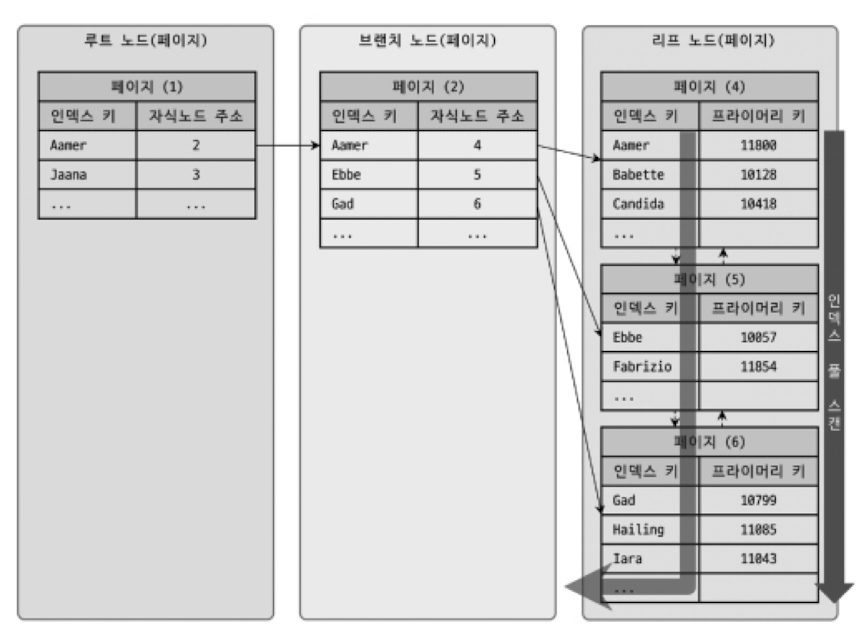
- 위 그림은 인덱스 풀 스캔 처리 방식을 표현한 것임.
- 인덱스의 리프 노드의 제일 앞 혹은 제일 뒤로 이동한 후 인덱스의 리프 노드를 연결하는 링크드 리스트를 따라, 처음부터 끝까지 스캔하는 방식임.
- 인덱스 레인지 스캔보다는 빠르지 않지만, 테이블 풀 스캔보다는 효율적임.
- 인덱스에 포함된 칼럼만으로 처리할 수 있는 경우, 테이블 레코드를 읽을 필요가 없기 때문.
- 인덱스 전체 크기는 테이블 자체 크기보다 훨씬 작으므로 테이블 전체를 읽는 것보다는 적은 디스크 I/O로 쿼리를 처리할 수 있음.
- 인덱스 레인지 스캔보다는 빠르지 않지만, 테이블 풀 스캔보다는 효율적임.
“인덱스를 사용한다” 라고 표현하면 “인덱스 레인지 스캔” 이나 뒤에 설명할 “루스 인덱스 스캔” 방식을 사용한다는 것을 의미함.
인덱스 풀 스캔 방식 또한 인덱스를 이용하는 방식이지만 효율적인 방식이 아니며, 일반적인 인덱스 생성 목적이 아님.
역으로, 테이블 전체를 읽거나 인덱스 풀 스캔 방식으로 인덱스를 사용한다면 “인덱스를 사용하지 못한다” 혹은 “인덱스를 효율적으로 사용하지 못한다” 로 표현한다.
루스 인덱스 스캔
- 오라클에서는 “인덱스 스킨 스캔” 이라는 기능과 작동 방식이 비슷함.
- MySQL 에서는 이를 “루스 인덱스 스캔” 이라고 함.
- 5.7까지는 루스 인덱스 스캔 기능이 많이 제한적이었음.
- 8.0 버전부터 다른 상용 DBMS에서 지원하는 인덱스 스킨 스캔과 같은 최적화를 조금씩 지원하기 시작함.
- 앞서 “인덱스 레인지 스캔”과 “인덱스 풀 스캔”은 “루스 인덱스 스캔”과 상반된 의미임.
- “인덱스 레인지 스캔”과 “인덱스 풀 스캔”을 “타이트(Tight) 인덱스 스캔” 으로 분류함.
- 루스 인덱스 스캔은, 말 그대로 느슨하게, 듬성듬성하게 인덱스를 읽는 것을 의미함.
- 인덱스 레인지 스캔과 비슷하게 작동하지만, 중간에 필요치 않은 인덱스 키 값은 무시(SKIP)하고 다음으로 넘어가는 형태로 처리됨.
- 일반적으로 GROUP BY, 또는 집합 함수 가운데 MAX(), MIN() 함수에 대해 최적화를 하는 경우에 사용됨.
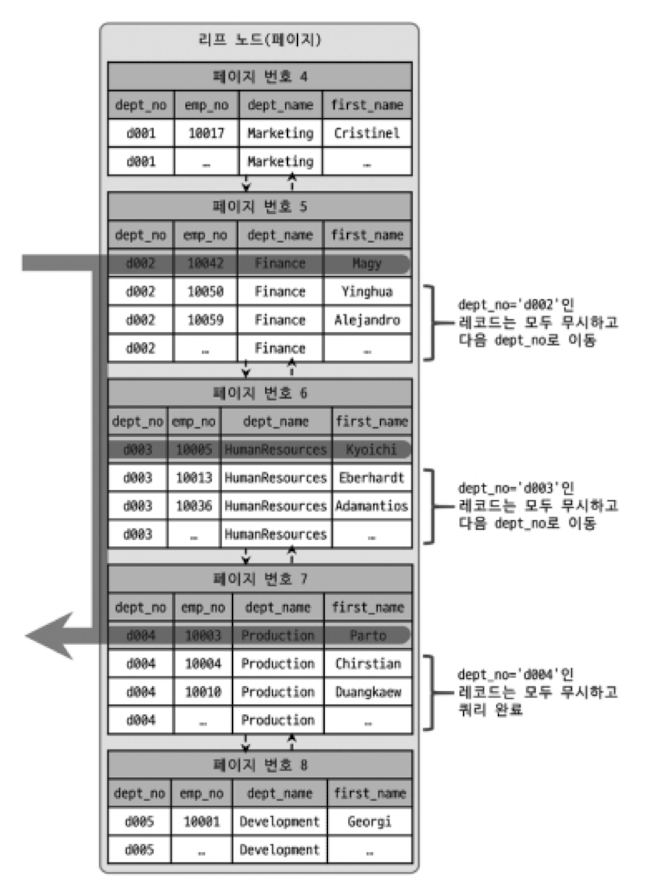
- 위 그림은
SELECT dept_no, MIN(emp_no) FROM dept_emp WHERE dep_no BETWEEN 'd002' AND 'd004' GROUP BY dept_no;쿼리에 대한 루스 인덱스 스캔을 표현함.- dept_emp 테이블에는 dept_no와 emp_no 두 개의 칼럼으로 인덱스가 생성되어 있음.
- dep_name과 first_name 칼럼은 참조용으로 표시된다.
- (dept_no, emp_no) 조합으로 정렬되어 있음.
- dept_no 그룹별로 첫 번째 레코드의 emp_no 값만 읽으면 됨.
- 즉, 인덱스에서 WHERE 조건을 만족하는 범위 전체를 다 스캔할 필요 없다는 걸 옵티마이저가 알고 있기 때문에, 조건에 만족하지 않는 레코드는 무시하고 다음 레코드로 이동함.
- 그림에서 회색 바탕 색깔의 레코드만 읽었음을 알 수 있음.
- 루스 인덱스 스캔을 사용하려면 여러 가지 조건을 만족해야 함.
- 이 제약조건은 10장 ‘실행 계획’ 에서 언급 예정.
인덱스 스킵 스캔
- 데이터베이스 서버에서 인덱스의 핵심은 값이 정렬되어 있다는 것임.
- 이로 인해 인덱스를 구성하는 칼럼의 순서가 매우 중요함.
- ex) employees 테이블
mysql> ALTER TABLE employees
ADD INDEX ix_gender_birthdate (gender, birth_date);- 위 인덱스를 사용하려면 WHERE 조건절에서 gender 칼럼에 대한 비교조건이 필수가 됨.
// 인덱스를 사용 하지 못하는 쿼리
mysql> SELECT * FROM employees WHERE birth_date >= '1965-02-01';
// 인덱스를 사용할 수 있는 쿼리
mysql> SELECT * FROM employees WHERE gender='M' AND birth_date >= '1965-02-01';- 위와 같은 쿼리를 사용해야 한다면, birth_Date 칼럼부터 시작하는 인덱스를 새로 생성해야 함.
- 8.0 버전 부터, 옵티마이저가 gender 칼럼을 건너뛰어서 birth_date 칼럼만으로도 인덱스 검색이 가능하게 해주는
인덱스 스킵 스캔(Index skip scan)최적화 기능이 도입됨. - 물론, 8.0 이전버전에도 인덱스 스킵 스캔과 비슷한 최적화를 수행하는 루스 인덱스 스캔(Loose index scan) 기능이 있었지만, GROUP BY 작업을 처리하기 위해 인덱스를 사용하는 경우에만 적용할 수 있었음.
- 인덱스 스킵 스캔은 WHERE 조건절의 검색을 위해 사용가능하도록 용도가 훨씬 넓어진 것임.
mysql> SET optimizer_switch='skip_scan=off';
mysql> EXPLAIN
SELECT gender, birth_date
FROM employees
WHERE birth_Date >= '1965-02-01';
+----+-----------+-------+---------------------+--------------------------+
| id | table | type | key | Extra |
+----+-----------+-------+---------------------+--------------------------+
| 1 | employees | index | ix_gender_birthdate | Using where; Using index |
+----+-----------+-------+---------------------+--------------------------+- 위 WHERE 절 에서 gender 칼럼에 대한 조검 없이 birth_date 칼럼의 비교 조건만 가지고 있기에 쉽게 ix_gender_birthdate 인덱스를 효율적으로 이용할 수 없음.
- 여기서 “효율적”으로 이용한다는 것은 “인덱스를 이용한다”와 동일한 표현임.
- 인덱스에서 꼭 필요한 부분만 접근한다는 것을 의미함.
- 위 실행 계획에서 type 칼럼이 “index” 라고 표시된 것은 인덱스를 처음부터 끝까지 모두 읽었다 (인덱스 풀 스캔)는 의미 임. → 인덱스를 비 효율적으로 사용한 것임.
- 이 예제는, gender, birth_Date 칼럼만 있으면 처리를 완료할 수 있기에 ix_gender_birthdate 인덱스를 풀 스캔한 것임.
- 만약 예제 쿼리가 employees 테이블의 모든 칼럼을 가져와야 했다면 테이블 풀 스캔을 실행했을 것임.
- 8.0 부터 도입된 인덱스 스킵 스캔을 활성화하고 동일한 실행 계획을 확인해 보자.
mysql> SET optimizer_switch='skip_scan=on';
mysql> EXPLAIN
SELECT gender, birth_date
FROM employees
WHERE birth_Date >= '1965-02-01';
+----+-----------+-------+---------------------+----------------------------------------+
| id | table | type | key | Extra |
+----+-----------+-------+---------------------+----------------------------------------+
| 1 | employees | range | ix_gender_birthdate | Using where; Using index for skip scan |
+----+-----------+-------+---------------------+----------------------------------------+- 이번에는 쿼리 실행 계획에서 type 칼럼 값이 “range” 로 표시됨.
- 인덱스에서 꼭 필요한 부분만 읽었다는 것을 의미함.
- 실행 계획의 Extra 칼럼에 “Using index for skip scan” 이라는 문구가 표시됨.
- 이는 ix_gender_birthdate 인덱스에 대해 인덱스 스킵 스캔을 활용해 데이터를 조회했다는 것을 의미함.
- MySQL 옵티마이저는 우선 gender 칼럼에서 유니크한 값을 모두 조회한 다음, 주어진 쿼리에 gender 칼럼의 조건을 추가해서 쿼리를 다시 실행하는 형태로 처리함.
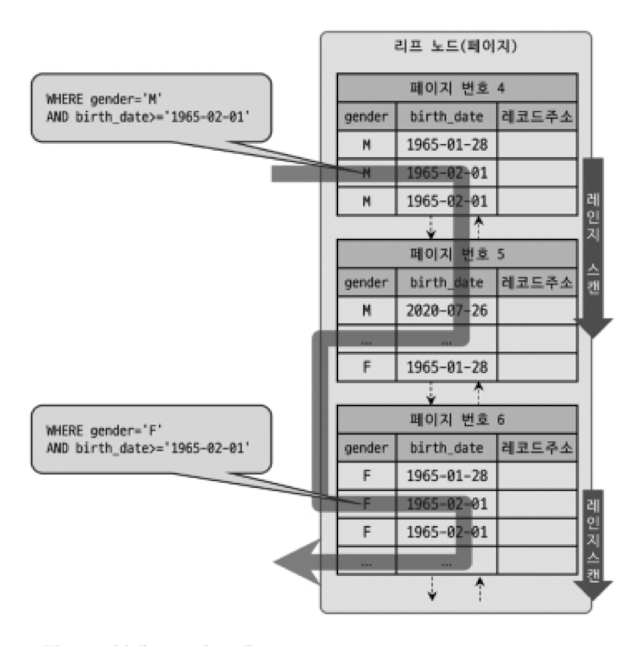
- 위 그림은 인덱스 스킵 스캔이 어떻게 처리되는지 보여줌.
- gender 칼럼은 성별을 구분하는 칼럼으로 ‘M’ 과 ‘F’ 값만 가지는 ENUM 타입의 칼럼임.
- 그래서 gender 칼럼에 대해 가능한 값 2개(’M’, ‘F’)를 구한 다음, 옵티마이저는 내부적으로 아래 2개의 쿼리를 실행 하는 것과 비슷한 형태의 최적화를 실행하게 됨.
mysql> SELECT gender, birth_date FROM employees WHERE gender='M' AND birth_date >= '1965-02-01';
mysql> SELECT gender, birth_date FROM employees WHERE gender='F' AND birth_date >= '1965-02-01';gender 칼럼이 ENUM(’M’, ‘F’) 타입이기때문에 위 처리가 가능한 건 아님. 칼럼이 어떤 타입이더라도 MySQL 서버는 인덱스를 루스 인덱스 스캔과 동일한 방식으로 읽으면서 인덱스에 존재하는 모든 값을 먼저 추출하고 그 결과를 이용해 인덱스 스킵 스캔을 실행함.
- 인덱스 스킵 스캔은 MySQL 8.0 버전에 새롭게 도입된 기능이어서 아직 다음과 같은 단점이 있음.
- WHERE 조건절에는 조건이 없는 인덱스의 선행 칼럼의 유니크한 값의 개수가 적어야 함.
- 이 조건은 쿼리 실행 계획의 비용과 관련된 부분임.
- 만약 유니크한 값의 개수가 매우 많다면 MySQL 옵티마이저는 인덱스에서 스캔해야 할 시작 시점을 검색하는 작업이 많이 필요해짐.
- 그래서 쿼리의 처리 성능이 오히려 더 느려질 수 있음.
- ex) (emp_no, dept_no) 조합으로 만들어진 인덱스에서 스킵 스캔을 실행한다고 가정하면 사원의 수만큼 레인지 스캔 시작 지점을 검색하는 작업이 필요해져서 쿼리의 성능이 매우 떨어짐.
- 그래서 인덱스 스킵 스캔은 인덱스의 선행 칼럼(위 예시의 경우 emo_no)이 가진 유니크한 값의 개수가 소량일 때만 적용 가능한 최적화임.
- 쿼리가 인덱스에 존재하는 칼럼만으로 처리 가능해야 함(커버링 인덱스)
- 아래 예제 쿼리를 보자.
mysql> EXPLAIN SELECT * FROM employees WHERE birth_date >= '1965-02-01'; +----+-----------+------+------+-------------+ | id | table | type | key | Extra | +----+-----------+------+------+-------------+ | 1 | employees | ALL | NULL | Using where | +----+-----------+------+------+-------------+- 이 쿼리는 WHERE 조건절은 동일하지만 SELECT 절에서 employees 테이블의 모든 칼럼을 조회하도록 변경함.
- 이 쿼리는 ix_gender_birthdate 인덱스에 포함된 gender 칼럼과 birth_date 칼럼 이외의 나머지 칼럼도 필요로 하므로 인덱스 스킵 스캔을 사용하지 못함.
- 풀 테이블 스캔으로 실행 계획을 수립한것을 확인할 수 있음.
- 이 제약 사항은 MySQL 서버의 옵ㅌ니마이저가 개선되면 충분히 해결될 수 있는 부분임.
- WHERE 조건절에는 조건이 없는 인덱스의 선행 칼럼의 유니크한 값의 개수가 적어야 함.
'Book > Real Mysql 8.0' 카테고리의 다른 글
| 책너두 (Real MySQL 8.0 1권) 23일차 (~257p) (1) | 2023.01.28 |
|---|---|
| 책너두 (Real MySQL 8.0 1권) 22일차 (~246p) (0) | 2023.01.28 |
| 책너두 (Real MySQL 8.0 1권) 20일차 (~229p) (1) | 2023.01.26 |
| 책너두 (Real MySQL 8.0 1권) 19일차 (~215p) (0) | 2023.01.24 |
| 책너두 (Real MySQL 8.0 1권) 18일차 (~203p) (0) | 2023.01.23 |